
Webscraping for Filmography Recommendations
This blog post was created for my PIC16B class at UCLA (Previously titled: Blog Post 2 - Webscraping for Filmography Recommendations).
In the age of Netflix, Amazon Prime, and Disney+, it seems as though the question on the tip of everyone’s tongue is “What should I binge next?” Wouldn’t it be lovely to find new movie or TV show recommendations based on your preferences? Never fear, in this post I will outline how we might be able to achieve the same using a webscraper to extract filmography recommendations.
Specifically, in this post I will be describing how my webscraper extracts the names of movies and TV shows that share actors with my favorite film, “Pride & Prejudice (2005)” (the IMDB page for this film is displayed below). I will be recommending new movies and TV shows based on the idea that if “Pride & Prejudice (2005)” shares actors with another movie or TV show (let this filmography be X), then it is likely that I would also enjoy filmography X.
Part 1: The Webscraper
In simple terms, webscraping refers to the act of extracting data from a selected website. The information or data is then exported into a format that is useful (such as .csv or .txt files) for the user. While it is true that data can be scrapped from the web through manual means (e.g., one rudimentary method of scraping data is the simple copy and paste method), this can often be a slow and tedious process. Automating the webscrapping process leads to the aggretation of information at much faster rate and also presents information in an easily interpretable manner.
The first step in the webscraping process is to ensure that we have successfully loaded scrapy, the package that will allow us to scrape data from the web. In my case, since I use anaconda, this would require me to activate the conda environment with the loaded scrapy package. The next step would be to start a new project by typing the following lines of code into the command line. Note that I have enclosed the environment name and project name within square brackets as these are arbitrary (Beware: you should remove the square brackets when you actually type in the environment and project names of your choice).
conda activate [environment name]
scrapy startproject [project name]
In my case, my conda environment name is PIC16B and I have decided to name this project IMDB_scraper. So the code I type in will be as follows:
conda activate PIC16B
scrapy startproject IMDB_scraper
Now that we have created our project, we must remember to work in our newly created project directory! We can enter this directory by entering the following in the command line. Recall that my project name is “IMDB_scraper” (Note that you will need to replace “IMDB_scraper” with your chosen project name).
cd IMDB_scraper
You might have noticed that your new project directory contains a number of files and/or folders. However, the ones we need to worry about are the settings.py file and spiders folder. Before writing our scraper we should add the following line of code to our settings.py file.
CLOSESPIDER_PAGECOUNT = 20
The reason for this is simple: while we are still writing, testing, and debugging out webscraper, we do not want to risk downloading too much data! This way, we limit the amount of data we download while ensuring our webscraper is working correctly. When we are sure that the webscraper is working, we can head back to our settings.py file and comment out the above line.
Now that we have dealt with the little details, we can finally navigate to our spiders folder and create our main .py file that will enable us to scrape data from the required IMDB pages. Within this .py file we will be writing our Spider class which inherits from scrapy.Spider and defines how a given website will be scraped. I’ve decided to call my main .py file imdb_spider.py and my Spider class IMDB_spider which has the following boilerplate code.
# Importing the scrapy package
import scrapy
class IMDB_spider(scrapy.Spider):
name = "imdb_spider"
# The following URL is for the Pride & Prejudice (2005)
# IMDB page. Note that it may be replaced with any other
# IMDB url
start_urls = [
"https://www.imdb.com/title/tt0414387/"
]
Within this IMDB_spider class, I’ve implemented three different parsing methods: parse which parses and then navigates from the main IMDB filmography page to the “Cast & crew” page, parse_full_credits which parses the “Full Cast & Crew” page and navigates to each respective actor’s page, and parse_actor_page which parses each individual cast member’s page and yields their respective films and TV shows in a dictionary. The three methods are described in greater detail below.
The parse(self, response) method parses the main IMDB page for “Pride & Prejudice (2005)” (link: https://www.imdb.com/title/tt0414387/) and navigates to the “Cast & crew” page. Note that the url for the “Cast & crew” page has the format <original_url>fullcredits/, hence we have the following:
def parse(self, response):
"""
Parses the main "Pride & Prejudice (2005)" IMDB page and
navigates to the the Cast & crew page
"""
cast_crew_url = response.url + "fullcredits"
# Navigating to the cast & crew page using scrapy.Request
# Once navigated to the above url, the parse_full_credits method
# will be implemented
yield scrapy.Request(cast_crew_url, callback=self.parse_full_credits)
The parse_full_credits(self, response) method parses the Series Cast section (url: https://www.imdb.com/title/tt0414387/fullcredits) and navigates to the individual actor pages. By using the developer tools embedded into chrome, we note that the cast member information is located within the following html code: <table class="cast_list">, as displayed in the following image. Hence, we can extract the hyperlink information using our handy .attrib function. However, we note that there are three links associated with each cast member - we only want the link corresponding to the image of the cast member.
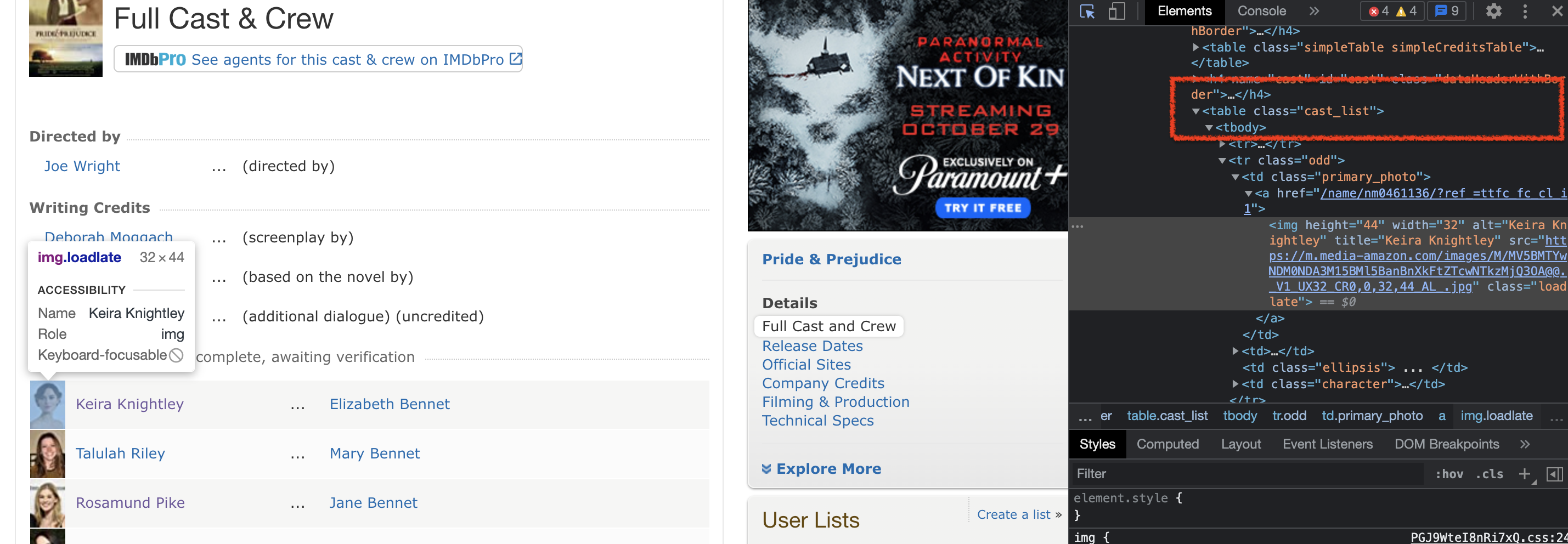
The cast_links variable in the following parse method stores the url segments following https://www.imdb.com and each cast member url has the format https://www.imdb.com/name/*, so we need only search for url segments that begin with /name.
We may then loop through the list of url segments, use the response.urljoin function to join the two url segments, and navigate to the respective actor pages by calling the parse_actor_page method.
def parse_full_credits(self, response):
"""
Parses the Series Cast Page for "Pride & Prejudice (2005)"
and navigates to each actor's page
"""
# Extracting links to the cast page
cast_links = [actor.attrib["href"] for actor in response.css("table.cast_list a")]
cast_imgs_links = [link for link in set(cast_links) if link.startswith("/name")]
for cast_link in cast_imgs_links:
url = response.urljoin(cast_link)
yield scrapy.Request(url, callback=self.parse_actor_page)
The parse_actor_page(self, response) method parses through the actor page and yields a dictionary with key-value pairs in the following format:
{
"actor_name" : actor_name,
"movie_or_TV_name" : movie_or_TV_name
}
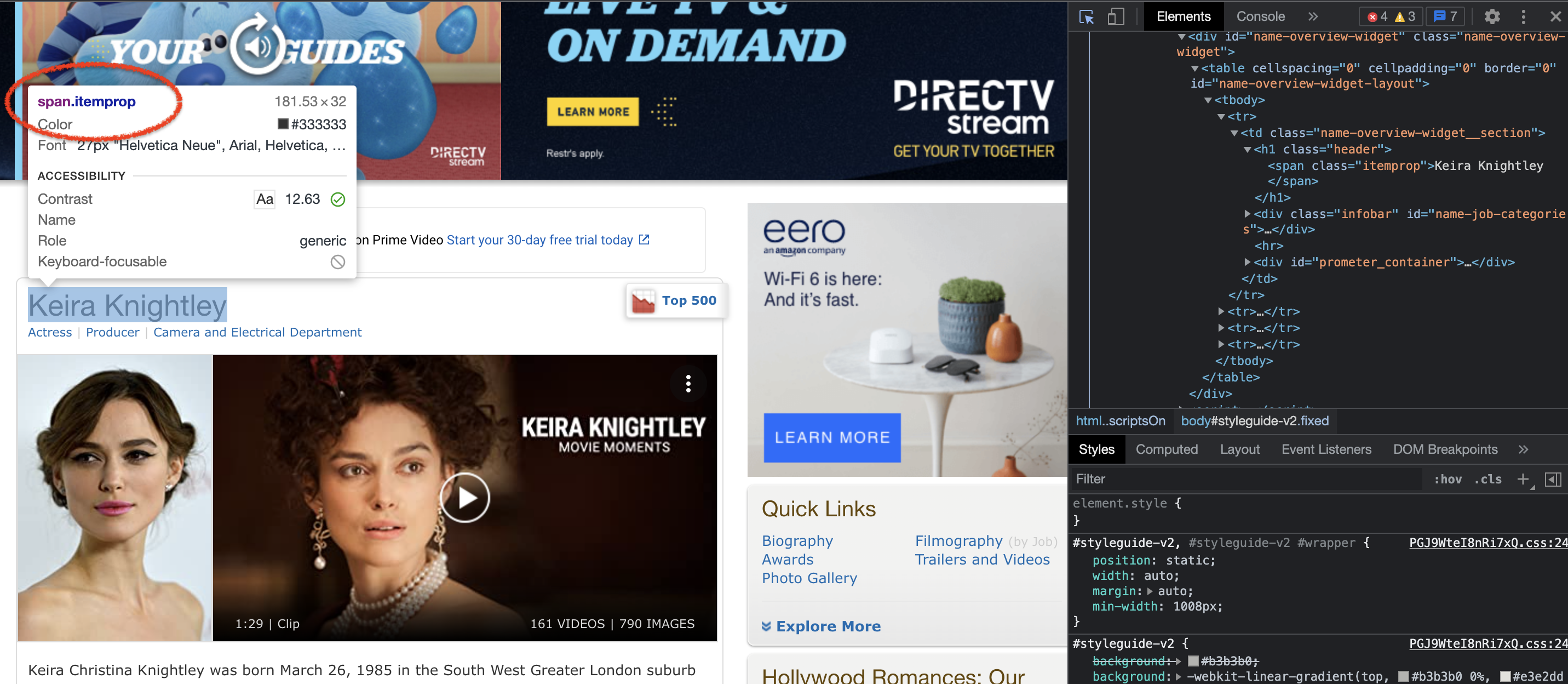
After navigating to the actor page (e.g., Keira Knightley’s IMDB page, shown in the above image, has the following url: https://www.imdb.com/name/nm0461136/) we note that the actor name is stored withn span.itemprop, making it possible for us to extract the actor name information. Also note that the actor’s filmography section is located within <div class="filmo-category-section b">. Therefore, we may define the parse_actor_page method as follows:
def parse_actor_page(self, response):
"""
Parses the actor page and stores the shared actor
information within a dictionary
"""
# extracting the actor name
actor_name = response.css("span.itemprop").get().split("<")[-2].split(">")[-1]
# all filmography information
all_films = response.css("div.filmo-category-section b").getall()
# looping through all the filmography information and extracting the
# filmography names
for film in all_films:
movie_or_TV_name = film.split("<")[-3].split(">")[-1]
# Yielding information in a key-value pair dictionary
yield {
"actor_name" : actor_name,
"movie_or_TV_name" : movie_or_TV_name
}
Now that we have successfully defined the Spider class, we are now ready to test out our webscraper! To do so, we run the following command and create a .csv file with the actor names and their respective filmography.
scrapy crawl imdb_spider -o movies.csv
Once we have checked the .csv file and made sure that our webscraper works correctly, recall that we must navigate to our settings.py file and comment out our earlier placed restriction, CLOSESPIDER_PAGECOUNT = 20. Now, we will re-run the same command, but instead we store all the shared actor information within a new .csv file (Note that I’ve called my new .csv file results.csv).
scrapy crawl imdb_spider -o results.csv
The full documentation for my webscraper function can be found on the following github page: https://github.com/mansakrishna23/filmography-scraper
Part 2: Deducing Filmography Recommendations
Our work doesn’t end even though we have sucessfully scraped our data! Remember that we still need to parse through and analyze the data we have aggregated and make filmography recommendations! To do so, we may read in out .csv file using Pandas (Don’t forget to import useful Python packages for your analysis)!
import pandas as pd
import numpy as np
films = pd.read_csv('IMDB_scraper/results.csv')
Remember that is it always good practice to check the data set you have imported!
# Checking the data set
films.head()
| actor_name | movie_or_TV_name | |
|---|---|---|
| 0 | Sylvester Morand | Agora |
| 1 | Sylvester Morand | The Seeker: The Dark Is Rising |
| 2 | Sylvester Morand | Ancient Rome: The Rise and Fall of an Empire |
| 3 | Sylvester Morand | The Brief |
| 4 | Sylvester Morand | Pride & Prejudice |
Since we would like to determine the number of shared actors in each of the movies and TV shows, we would need to count the number of times each movie or TV show name is repeated within the films dataset. Why is it possible for us to determine the number of shared actors this way? - Consider a film X. Suppose unique actors A and B worked in film X, it follows that we would have two shared actors corresponding to film X. Also note that film X would have to be repeated twice within our films data set. Therefore, we may safely assume that the number of shared actors for all filmography corresponds to the frequency of each movie/TV show in the above films dataset!
# Storing the unique filmography in an array as strings
unique_films = films['movie_or_TV_name'].unique()
unique_films = np.array(unique_films).astype(str)
unique_films # checking the array
array(['Agora', 'The Seeker: The Dark Is Rising',
'Ancient Rome: The Rise and Fall of an Empire', ...,
'VM Show Vol. 2', '41 premis Sant Jordi de cinematografia',
'Mike Leigh on Secrets and Lies'], dtype='<U86')
# initializing the array to zeros
freq = np.zeros(len(unique_films))
# all filmography
all_films = np.array(films['movie_or_TV_name']).astype(str)
# looping through the unique filmography
for n, film_name in enumerate(unique_films):
for film in all_films:
if film == film_name:
# incrementing the number of shared
# actors
freq[n] += 1
# we will now check the frequency of each movie/TV show
# which will give us the number of shared actors
freq
array([1., 1., 2., ..., 1., 1., 1.])
Now that we have successfullt determined the number of shared actors per filmography, let us create a new dataframe using Pandas!
df = pd.DataFrame()
df['movie/TV show'] = unique_films
df['number of shared actors'] = freq
df
| movie/TV show | number of shared actors | |
|---|---|---|
| 0 | Agora | 1.0 |
| 1 | The Seeker: The Dark Is Rising | 1.0 |
| 2 | Ancient Rome: The Rise and Fall of an Empire | 2.0 |
| 3 | The Brief | 2.0 |
| 4 | Pride & Prejudice | 37.0 |
| ... | ... | ... |
| 2634 | 54th Golden Globe Awards | 1.0 |
| 2635 | The Smith & Jones Sketchbook | 1.0 |
| 2636 | VM Show Vol. 2 | 1.0 |
| 2637 | 41 premis Sant Jordi de cinematografia | 1.0 |
| 2638 | Mike Leigh on Secrets and Lies | 1.0 |
2639 rows × 2 columns
Notice that our fourth film is “Pride & Prejudice (2005)”. We can safely remove this from the dataset since we are recommending other movies and TV shows to “Pride & Prejudice (2005)” enthusiasts.
| movie/TV show | number of shared actors | |
|---|---|---|
| 0 | Agora | 1.0 |
| 1 | The Seeker: The Dark Is Rising | 1.0 |
| 2 | Ancient Rome: The Rise and Fall of an Empire | 2.0 |
| 3 | The Brief | 2.0 |
| 5 | Fingersmith | 1.0 |
| ... | ... | ... |
| 2634 | 54th Golden Globe Awards | 1.0 |
| 2635 | The Smith & Jones Sketchbook | 1.0 |
| 2636 | VM Show Vol. 2 | 1.0 |
| 2637 | 41 premis Sant Jordi de cinematografia | 1.0 |
| 2638 | Mike Leigh on Secrets and Lies | 1.0 |
2638 rows × 2 columns
Suppose we only want the top ten movie/TV show recommendations! We would need to choose only those movies/TV shows with the highest number of shared actors. So, let’s sort the movies and TV shows accordingly!
# Let's sort the movies and TV shows according the number of shared actors (greatest no. to lowest no.)
shared_actors = sorted(zip(freq, unique_films), reverse=True)
# Extracting the film names
filmography = np.array([])
counts = np.array([])
for x, y in shared_actors:
filmography = np.append(filmography, y)
counts = np.append(counts, x)
df_sorted = pd.DataFrame()
df_sorted['movie/TV show'] = filmography
df_sorted['number of shared actors'] = counts
df_sorted
| movie/TV show | number of shared actors | |
|---|---|---|
| 1 | The Bill | 13.0 |
| 2 | Pride and Prejudice Revisited | 13.0 |
| 3 | Pride & Prejudice: The Life and Times of J... | 13.0 |
| 4 | Breakfast | 13.0 |
| 5 | Made in Hollywood | 11.0 |
| ... | ... | ... |
| 2634 | 007 Legends | 1.0 |
| 2635 | 'NYPD Blue': A Final Tribute | 1.0 |
| 2636 | 'Donnie Darko': Production Diary | 1.0 |
| 2637 | 'Calendar Girls': The Naked Truth | 1.0 |
| 2638 | 'Calendar Girls': Creating the Calendar | 1.0 |
2638 rows × 2 columns
Now, let’s recommend the first 10 movies in the above data frame!!
recommendations = df_sorted[0:10]
recommendations
| movie/TV show | number of shared actors | |
|---|---|---|
| 1 | The Bill | 13.0 |
| 2 | Pride and Prejudice Revisited | 13.0 |
| 3 | Pride & Prejudice: The Life and Times of J... | 13.0 |
| 4 | Breakfast | 13.0 |
| 5 | Made in Hollywood | 11.0 |
| 6 | Entertainment Tonight | 11.0 |
| 7 | Doctor Who | 11.0 |
| 8 | The Graham Norton Show | 10.0 |
| 9 | Pride & Prejudice: The Bennets | 10.0 |
| 10 | Pride & Prejudice: On Set Diaries | 10.0 |
Congratulations! We’ve successfully extracting our top ten recommendations! But wait, notice that the scraper was unable to correctly scraper the ampersand symbol! As always, we may need to modify the strings a little to improve the readability of our suggestions!
recommendations = recommendations.replace("Pride & Prejudice: The Bennets", "Pride & Prejudice: The Bennets")
recommendations = recommendations.replace("Pride & Prejudice: The Life and Times of Jane Austen",
"Pride & Prejudice: The Life and Times of Jane Austen")
recommendations = recommendations.replace("Pride & Prejudice: On Set Diaries", "Pride & Prejudice: On Set Diaries")
recommendations
| movie/TV show | number of shared actors | |
|---|---|---|
| 1 | The Bill | 13.0 |
| 2 | Pride and Prejudice Revisited | 13.0 |
| 3 | Pride & Prejudice: The Life and Times of Jane ... | 13.0 |
| 4 | Breakfast | 13.0 |
| 5 | Made in Hollywood | 11.0 |
| 6 | Entertainment Tonight | 11.0 |
| 7 | Doctor Who | 11.0 |
| 8 | The Graham Norton Show | 10.0 |
| 9 | Pride & Prejudice: The Bennets | 10.0 |
| 10 | Pride & Prejudice: On Set Diaries | 10.0 |
In the end, we have successfully extracted recommendations for “Pride & Prejudice (2005)” enthusiasts via webscraping!
As far as this particular project was concerned, undoubtedly the most tedious part was writing the webscraper and identifying the correct HTML/CSS code that would allow us to extract the appropriate data! For this, found it particularly helpful to navigate through the websites in advance (manually) and explore the developer code beforehand. A lesson learned was to scrape only the required data; in order words I had to identify the information I needed and plan how I was going to store it in advance - it would have been really inefficient if I were to simply scrape the entire site!